Skip to Content
AnnotaPipeline: Integrating Multi-Omics Data for Precise Eukaryotic Protein Annotation
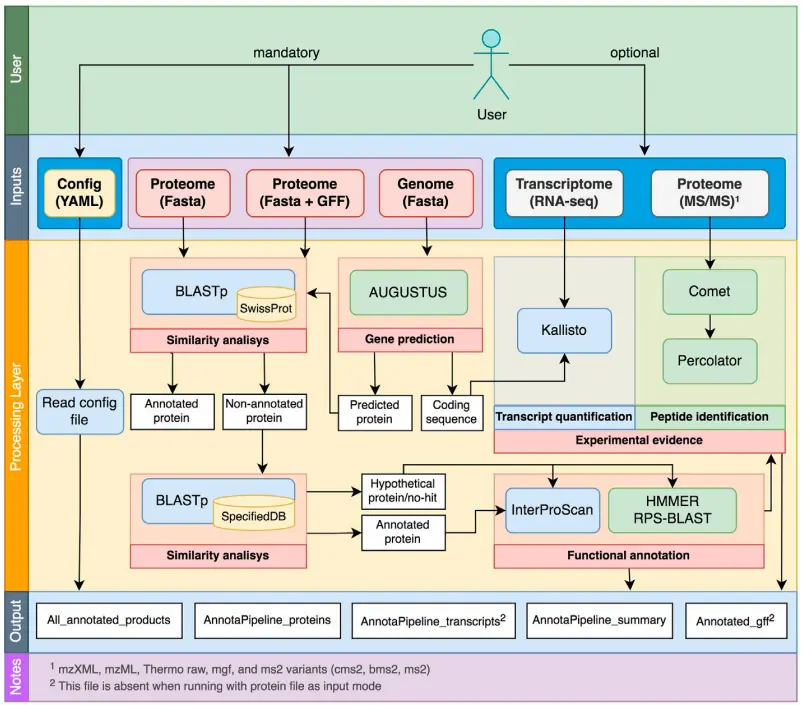
Comprehensive and accurate annotation of eukaryotic proteins is essential for understanding cellular function, disease mechanisms, and evolutionary biology. AnnotaPipeline provides an integrated multi-omics workflow that leverages transcriptomic, proteomic, and genomic datasets to refine protein annotations with exceptional accuracy. By correlating RNA expression profiles with mass spectrometry-derived peptide evidence, AnnotaPipeline validates existing protein-coding genes, identifies previously unannotated proteins, and uncovers alternative isoforms. This holistic approach ensures that protein annotations are supported by multiple layers of experimental evidence, enhancing reliability and functional insight. Designed for both model and non-model organisms, AnnotaPipeline streamlines the annotation process, making it an invaluable tool for researchers seeking to translate complex omics data into biologically meaningful knowledge.